
Introduction
Brand name normalization rules are one of those things nobody talks about — until the data breaks.
I was working with a mid-size e-commerce company a couple of years ago. Their marketing team was running reports from Shopify, Salesforce, and Google Analytics. Every platform showed different numbers for the same brand campaigns. Nobody could agree on which number was right.
The problem? The same brand name was stored 14 different ways across their systems. “Nike,” “NIKE,” “Nike Inc.,” “nike.com,” “NIKE®,” and “Nike Incorporated” were all sitting in separate rows — treated as 14 different companies.
Their sales attribution was broken. Their CRM was full of duplicates. And their quarterly reports were basically fiction.
One week of normalization work fixed everything.
That is what this guide is about. Brand name normalization rules are not a technical luxury for enterprise teams. They are a basic requirement for any business that wants to trust its own data.
Key Takeaways
- Brand name normalization rules convert inconsistent brand name variations into one clean, standard format
- Up to 60% of data anomalies result from poor normalization practices
- Organizations lose an average of $12.9 million per year to poor data quality
- Normalization affects your CRM accuracy, analytics, SEO entity recognition, and ad attribution
- It is not a one-time task — it must run continuously at every point of data entry
- AI helps but rules come first — even the best AI hallucinates brand names without a rule engine
What Are Brand Name Normalization Rules?
Brand name normalization rules are a structured, ordered set of transformations applied to raw company name data to convert any variation into a single, agreed-upon canonical form. The canonical name is the one authoritative version of a brand name your organization uses everywhere — in your CRM, your data warehouse, your invoices, and your schema markup. Samar Iqbal Digital
Simple example:
These five entries all refer to the same company:
- Apple Inc.
- APPLE
- apple
- Apple®
- Apple Incorporated
After normalization, every single one becomes: Apple
That one canonical version is what gets stored, reported, and used across every system.
Without clear rules for normalization, these variations can create inaccurate reports, fragmented analytics, and inconsistent customer experiences.
Why Brand Name Normalization Matters in 2026
Five years ago, most businesses had three or four data sources to manage. Today that number is closer to fifteen or twenty.
Today, that number is closer to fifteen or twenty — Shopify, Salesforce, Google Analytics 4, Meta Ads Manager, Amazon — each one ingesting brand names from different sources, in different formats, with different conventions.
Every new data source is a new opportunity for brand name inconsistency to sneak in.
Here is what bad normalization actually costs you:
Broken attribution: Your ads show conversions for “Nike Inc.” Your CRM has revenue under “NIKE.” Your analytics platform tracks “nike.com.” None of them match. You cannot calculate true ROI.
CRM duplicates: Bad CRM data costs B2B companies an estimated 20–30% of their sales and marketing budget — through duplicate outreach, inaccurate segmentation, and broken attribution.
Weak SEO entity signals: Consistent brand name usage across your site, structured data (Schema.org), and external platforms strengthens entity recognition signals. Google’s Knowledge Graph uses these signals to associate your content with brand entities, which influences branded search rankings and appearance in AI-generated overviews.
Investor and board reporting errors: When your numbers do not match across platforms, it destroys confidence — internally and externally.
The Core Brand Name Normalization Rules (Step by Step)
These are the rules that should form the backbone of any normalization system, from a small business spreadsheet to an enterprise MDM platform.
Rule 1: Define One Canonical Name
Before you apply any transformation, you need to decide what the correct version of each brand name actually is.
The canonical name is your single source of truth. It is the version that goes into every system, every report, and every piece of schema markup.
For most brands, the canonical name is simply the brand’s official trading name — not the legal entity name.
Examples:
- Nike, Inc. → Nike
- Microsoft Corporation → Microsoft
- The Coca-Cola Company → Coca-Cola
- International Business Machines → IBM
The canonical name should be stored in a master reference table that every system and every team member can access.
Rule 2: Standardize Capitalization
Inconsistent capitalization is the most common normalization problem. The same brand appears as “nike,” “NIKE,” and “Nike” in different systems.
The standard rule is Title Case for most brand names:
- apple → Apple
- SAMSUNG → Samsung
- amazon web services → Amazon Web Services
Exceptions to the capitalization rule:
Some brands have non-standard capitalization that is part of their identity and must be preserved:
- iPhone (not Iphone or IPHONE)
- eBay (not Ebay or EBAY)
- YouTube (not Youtube)
- LinkedIn (not Linkedin)
- adidas (officially lowercase — preserve it)
If your brand name is shorter than four characters, then you should use uppercase. Examples: IBM, 3M, UPS, H&M
This means your normalization system needs both a general capitalization rule AND an exceptions table for brands with non-standard styling.

Rule 3: Remove Legal Suffixes
Do not use Inc., LLC, Ltd., Corp., PLC, or GmbH. They do not look nice on the analytics dashboard and confuse users. Get rid of the legal suffix from operational use. Tech Business Online
Transformation examples:
- Nike, Inc. → Nike
- Microsoft Corporation → Microsoft
- MTG Management Consultants LLC → MTG Management Consultants
- Unilever PLC → Unilever
- KPMG GmbH → KPMG
The only exception: use legal suffixes when specifically required for legal documents, contracts, or official regulatory filings. In analytics, CRM, and marketing systems — strip them completely.
Common legal suffixes to remove:
- Inc. / Incorporated
- LLC / L.L.C.
- Ltd. / Limited
- Corp. / Corporation
- PLC / P.L.C.
- GmbH
- S.A. / S.A.S.
- Pty Ltd (Australia)
- Co. / & Co.
Rule 4: Remove Trademark and Copyright Symbols
Trademark and copyright symbols — ®, ™, and © — have no use in marketing and analytics. They only create machine failure and add additional noise. Brand name normalization rules strip them from the records. Tech Business Online
Examples:
- Apple® → Apple
- Kleenex™ → Kleenex
- Google© → Google
These symbols cause string matching failures in databases and create duplicate records that no deduplication algorithm will catch automatically.
Rule 5: Handle Special Characters Consistently
Brand name normalization rules standardize the use of special characters and punctuation. T
This is where things get nuanced. Some special characters are part of a brand’s identity and must be preserved. Others are data entry errors that must be removed.
Preserve these (brand identity characters):
- Ampersand in brand names: H&M, AT&T, M&Ms
- Hyphens in compound names: Coca-Cola, Häagen-Dazs
- Dots that are brand identity: S.C. Johnson, A.P. Moller
Remove these (data entry noise):
- Extra spaces before or after the name
- Double spaces between words
- Trailing punctuation (commas, periods)
- Parenthetical descriptors: “Nike (Footwear)” → Nike
ASCII vs Unicode: Convert “Rénault” to “Renault” and “München” to “Muenchen” if your audience expects ASCII. For global datasets, decide upfront whether you normalize diacritics or preserve them — and apply that rule consistently.
Rule 6: Expand or Standardize Abbreviations
Handle abbreviations intelligently — expand common ones where helpful (“Intl” → “International”) but preserve brand-specific short forms (“FedEx” stays “FedEx”).
Examples:
- Intl → International (unless it is part of a brand name)
- Mgmt → Management
- Corp → Remove entirely (see Rule 3)
- FedEx → FedEx (this IS the brand name — do not expand)
- IBM → IBM (do not expand to International Business Machines in operational systems)
The key distinction: is the abbreviation a brand identity choice, or is it a data entry shortcut? Brand identity abbreviations stay. Data entry shortcuts get corrected.
Rule 7: Handle Whitespace
This sounds trivial. It is not. Whitespace errors silently corrupt databases and cause string matching failures that are almost impossible to spot visually.
Rules for whitespace:
- Remove all leading spaces (spaces before the first character)
- Remove all trailing spaces (spaces after the last character)
- Collapse multiple internal spaces to single spaces
- ” Nike ” → “Nike”
- “Coca – Cola” → “Coca-Cola”
In SQL this is a simple TRIM() and REGEXP_REPLACE(). In Python it is .strip() and re.sub(). But if you do not have this rule explicitly documented, it will not get applied consistently across teams and systems.
Rule 8: Resolve Alternate Brand Names and Aliases
Some brands are known by multiple legitimate names. Your system needs to know that all of these are the same entity:
| Raw Input | Canonical Name |
|---|---|
| X | |
| X Corp | X |
| Meta Platforms | Meta |
| Meta | |
| Alphabet Inc. | |
| Google LLC | |
| Berkshire Hathaway | Berkshire Hathaway |
| Warren Buffett’s company | Berkshire Hathaway |
Update immediately when a major brand rebrands — Twitter becoming X is the obvious recent example. Brand identity changes happen, and your system needs to reflect them without creating a new wave of duplicates
This requires an alias table — a lookup that maps every known variation and former name to the current canonical form.
Rule 9: Apply Rules in the Correct Order
The sequence matters. Applying rules in the wrong order creates new errors.
Correct transformation order:
- Trim leading and trailing whitespace
- Remove trademark/copyright symbols (®, ™, ©)
- Remove legal suffixes (Inc., LLC, Corp.)
- Remove parenthetical descriptors
- Expand or correct abbreviations
- Apply capitalization rules
- Normalize special characters
- Collapse internal whitespace
- Check alias table for known variations
- Validate against canonical reference table
If you apply capitalization before removing legal suffixes, you might get “Nike, Inc.” normalized to “Nike, Inc” with a trailing comma — which then fails your suffix removal pattern. Order prevents these cascading errors.
Rule 10: Maintain a Living Normalization Playbook
Always document your rules in a shared Normalization Playbook. Update it quarterly as new data patterns emerge. The playbook should document canonical name decisions, exception lists for brands with non-standard styling, the order in which transformations run, and rules for edge cases like ampersands, numbers in names, and non-Latin characters.
This playbook is what makes normalization a system rather than a one-time project.
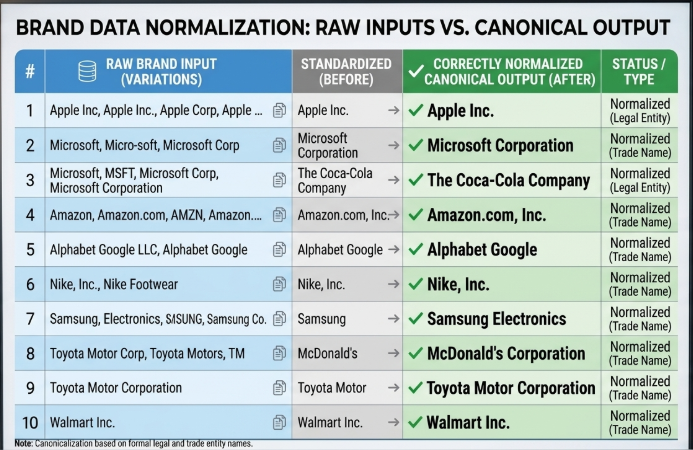
Before and After: Real Normalization Examples
| Raw Input | Problem | Normalized Output |
|---|---|---|
| apple inc. | Lowercase + legal suffix | Apple |
| SAMSUNG ELECTRONICS CO LTD | All caps + legal suffix | Samsung |
| nike® | Trademark symbol | Nike |
| Coca Cola | Missing hyphen | Coca-Cola |
| google llc | Lowercase + legal suffix | |
| McDonald’s Corporation | Legal suffix | McDonald’s |
| Lowercase + outdated name | X | |
| MICROSOFT CORP. | All caps + suffix | Microsoft |
| amazon.com Inc | Domain-style + suffix | Amazon |
| H & M | Extra spaces in ampersand | H&M |
Tools for Brand Name Normalization
| Tool | Best For | Price | Skill Level |
|---|---|---|---|
| OpenRefine | Small to medium datasets, manual cleaning | Free | Beginner |
| Python (pandas) | Automated pipelines, custom rules | Free | Intermediate |
| SQL (TRIM, REGEXP) | Database-level normalization | Free | Intermediate |
| dbt | Data warehouse transformations | Free/Paid | Advanced |
| Talend | Mid-enterprise data quality | Paid | Advanced |
| Informatica MDM | Large enterprise master data | Enterprise pricing | Expert |
| Google Sheets (VLOOKUP) | Small teams, quick fixes | Free | Beginner |
| Ataccama | AI-assisted data quality | Enterprise pricing | Expert |
Recommendation by business size:
- Small business (under 10,000 records): Start with Google Sheets and a well-structured VLOOKUP alias table. It is free and maintainable.
- Mid-size business: Python scripts with a pandas normalization pipeline plus OpenRefine for initial cleanup.
- Enterprise: A proper MDM platform like Informatica or Ataccama, with dbt handling warehouse-level transformations.
Brand Name Normalization for SEO
This is the angle most data management guides completely ignore — and it is hugely important.
Google does not just crawl your website. It builds an understanding of your brand as an entity. Consistent brand name usage across your website, your structured data, your Google Business Profile, your backlinks, and your social profiles all feed into Google’s entity recognition.
When these are inconsistent, Google gets confused about what your brand actually is. That confusion weakens your Knowledge Panel, your branded search rankings, and your appearance in AI Overviews.
SEO-specific normalization rules:
- Use the exact same brand name in your Schema.org Organization markup as you use everywhere else
- Make sure your Google Business Profile name matches your canonical brand name exactly
- Use consistent brand name formatting across all backlink anchor texts
- Your social media handles and display names should match your canonical brand name as closely as platform rules allow
Internal linking suggestion: Link to your article on “Schema Markup for Local SEO” or “Google Knowledge Panel Optimization”
Pros and Cons of Implementing Formal Normalization Rules
Pros
- Clean, trustworthy data across every system and every report
- Elimination of duplicate records in CRM and databases
- Accurate sales attribution and marketing ROI measurement
- Stronger Google entity recognition and SEO performance
- Faster, more reliable data processing and analytics
- Reduced manual data cleaning costs over time
Cons
- Initial setup requires significant time investment
- Requires coordination across marketing, IT, and legal teams
- Edge cases and exceptions require ongoing maintenance
- Rebrands (like Twitter → X) require immediate rule updates
- Even the best large language models hallucinate brand names — rules-first plus AI augmentation is the winning combo, not AI alone
Common Myths About Brand Name Normalization
Myth 1: “It’s just find-and-replace in Excel”
One-off scripts break the moment new variations appear. Real normalization needs a governed rule engine plus exception handling.
Myth 2: “AI will fix everything automatically”
AI helps — especially with fuzzy matching and detecting variations. But AI without a rule engine produces inconsistent results. Rules come first. AI augments rules.
Myth 3: “We only need to do this once”
It is a living standard. New data arrives daily. Your rules must run continuously at the point of entry. Normalization is a process, not a project.
Myth 4: “This only matters for big companies”
Any business with more than two data sources has a normalization problem. A small e-commerce store pulling data from Shopify, Klaviyo, and Google Ads will have brand name inconsistencies from day one.
Myth 5: “Normalization damages brand identity”
Normalization is not a rebranding exercise, and it is not about forcing your brand’s public-facing identity to be robotic and stripped of personality. Your logo can still have a stylized lowercase wordmark. Normalization is about your internal data — not your creative presentation.
Expert Tips
Tip 1: Build your alias table before you build your rule engine. The alias table — mapping every known variation to the canonical form — is more valuable than any transformation script.
Tip 2: Normalize at the point of entry. Cleaning data after it enters your system is ten times more expensive than validating it on the way in. Add normalization to your data intake forms, API connectors, and CRM entry fields.
Tip 3: Assign an owner. Normalization rules decay without ownership. Someone on your data or marketing ops team should be responsible for the playbook and quarterly reviews.
Tip 4: Do not trust user-generated brand name inputs. Website visitors, form submissions, and CSV uploads from clients will produce every possible variation. Always normalize on ingest — never assume incoming data is clean.
Tip 5: Track rebrand events. When a major brand changes its name — Twitter to X, Facebook to Meta, Google to Alphabet — your alias table needs updating immediately. Set up Google Alerts for major brands in your dataset.
Tip 6: Use fuzzy matching to catch what exact rules miss. Tools like Python’s fuzzywuzzy library or Levenshtein distance algorithms can catch near-matches that slip past exact-match rules — “Microsft” catching “Microsoft” for example.
Step-by-Step Implementation Guide
Step 1: Audit your current data Export 10,000 records from your primary system. Run a frequency analysis on brand name fields. Count how many unique variations exist for your top 50 brands. This number will shock you.
Step 2: Build your canonical reference table Create a master list of every brand name in your dataset with one agreed canonical form for each. This becomes your single source of truth.
Step 3: Build your alias table For every brand, list every known variation and map it to the canonical name. Start with your top 20 brands and expand from there.
Step 4: Document your transformation rules Write down the 10 core rules in this guide, adapted for your specific data. Include your exceptions list. Store this in a shared document that everyone can access.
Step 5: Implement in your pipeline Start with the system that feeds the most downstream tools — usually your CRM or data warehouse. Build normalization into the transformation layer before data reaches your analytics tools.
Step 6: Validate results After your first normalization run, spot-check 100 records manually. Look for edge cases your rules missed. Add them to your playbook.
Step 7: Automate and monitor Set your normalization rules to run automatically on every new data import. Build a monitoring alert for any brand name that does not match your canonical table — these are new variations you need to review.
FAQ Section
What are brand name normalization rules?
Brand name normalization rules are structured guidelines that standardize inconsistent brand name variations into one canonical format across all databases and systems. For example, “Apple Inc.,” “APPLE,” “apple®,” and “Apple Incorporated” all become “Apple” after normalization.
Why is brand name normalization important?
Without normalization, the same brand is stored multiple ways across different systems, creating duplicate records, broken attribution, inaccurate reporting, and weak SEO entity signals. Normalized data improves consistency for more than 75% of organizations that implement it.
Should I remove Inc., LLC, and Corp. from brand names?
Yes — in operational systems, analytics platforms, and CRM databases. Legal suffixes add no value in marketing and analytics contexts and cause string matching failures. Keep legal suffixes only in contracts, legal filings, and official regulatory documents.
How do I handle brands with unusual capitalization like iPhone or eBay?
Brands with non-standard capitalization as part of their identity must be handled through an exceptions table. Your general rule applies Title Case to most brands, but your exceptions table overrides that rule for specific brands where the capitalization is intentional.
What tools should I use for brand name normalization?
For small datasets, Google Sheets with VLOOKUP or OpenRefine work well. For medium-scale automated pipelines, Python with pandas is the most flexible option. For enterprise data warehouses, dbt transformations combined with an MDM platform like Informatica or Ataccama are the industry standard.
How often should I update my normalization rules?
Update your playbook quarterly as new data patterns emerge, and update immediately when a major brand rebrands. Normalization is a continuous process — not a one-time cleanup.
Does brand name normalization affect SEO?
Yes. Consistent brand name usage across your site, structured data, and external platforms strengthens entity recognition signals. Google’s Knowledge Graph uses these signals to associate your content with brand entities, which influences branded search rankings and appearance in AI-generated overviews.
What is a canonical brand name?
A canonical brand name is the single, agreed-upon authoritative version of a brand name that your organization uses everywhere. It is the standard against which all variations are measured and to which all variations are converted.
What is fuzzy matching in brand normalization?
Fuzzy matching is a technique that identifies brand name variations even when they are not identical — catching typos, transpositions, and near-matches that exact-match rules miss. For example, “Microsft” would fuzzy-match to “Microsoft” even though it is not an exact string match.
How do I handle brand rebrands in my normalization system?
Maintain an alias table that maps former brand names to current canonical names. When a brand rebrands — for example Twitter becoming X — add the old name as an alias pointing to the new canonical name. This prevents the rebrand from creating a wave of duplicate records.
Fazilat zulfiqar is an SEO specialist at RankWithLinks, focused on improving search rankings through smart link building and optimization.He helps businesses grow organic traffic and build strong online authority.
Fazilat zulfiqar
Fazilat zulfiqar is an SEO specialist at RankWithLinks, focused on improving search rankings through smart link building and optimization.He helps businesses grow organic traffic and build strong online authority.
